[warn] Restart data response bad code was received (0x00000005)
-
@chrishamm
Today I got the following error in the journalctl - while the printer was paused mid print.Jan 17 06:55:51 Meltingplot-MBL-480-vaswsq DuetControlServer[4211]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 17 06:55:51 Meltingplot-MBL-480-vaswsq DuetControlServer[4211]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 17 06:55:51 Meltingplot-MBL-480-vaswsq DuetControlServer[4211]: [info] Aborted macro file daemon.g Jan 17 06:55:51 Meltingplot-MBL-480-vaswsq DuetControlServer[4211]: [warn] SPI connection has been reset Jan 17 06:55:51 Meltingplot-MBL-480-vaswsq DuetControlServer[4211]: [info] Aborted job file Jan 17 06:56:00 Meltingplot-MBL-480-vaswsq DuetControlServer[4211]: [info] Starting macro file daemon.g on channel DaemonThe response code looks like the BadHeaderChecksum
enum TransferResponse : uint32_t { Success = 1, BadFormat = 2, BadProtocolVersion = 3, BadDataLength = 4, BadHeaderChecksum = 5, BadDataChecksum = 6, BadResponse = 0xFEFEFEFE };but the error message indicates, that it was received while waiting/transfering data.
From the eventlog
2024-01-17 06:55:51 Warning: SPI connection has been reset 2024-01-17 06:55:51 Connection to SBC established!M122 output
M122 === Diagnostics === RepRapFirmware for Duet 3 MB6HC version 3.5.0-rc.2 (2023-12-14 10:32:22) running on Duet 3 MB6HC v1.02 or later (SBC mode) Board ID: 08DJM-9P63L-DJ3T8-6JKD4-3SJ6K-9A77A Used output buffers: 1 of 40 (18 max) === RTOS === Static ram: 154844 Dynamic ram: 88920 of which 3424 recycled Never used RAM 95036, free system stack 124 words Tasks: SBC(2,ready,3.1%,402) HEAT(3,nWait,0.1%,324) Move(4,nWait,0.0%,213) CanReceiv(6,nWait,0.0%,942) CanSender(5,nWait,0.0%,334) CanClock(7,delaying,0.0%,342) TMC(4,nWait,24.8%,61) MAIN(2,running,71.9%,103) IDLE(0,ready,0.0%,30), total 100.0% Owned mutexes: HTTP(MAIN) === Platform === Last reset 19:10:03 ago, cause: software Last software reset at 2024-01-16 14:00, reason: User, none spinning, available RAM 95948, slot 2 Software reset code 0x6013 HFSR 0x00000000 CFSR 0x00000000 ICSR 0x0044a000 BFAR 0x00000000 SP 0x00000000 Task SBC Freestk 0 n/a Error status: 0x00 MCU temperature: min 33.0, current 33.3, max 33.8 Supply voltage: min 24.0, current 24.1, max 24.2, under voltage events: 0, over voltage events: 0, power good: yes 12V rail voltage: min 11.6, current 12.2, max 12.9, under voltage events: 0 Heap OK, handles allocated/used 99/7, heap memory allocated/used/recyclable 2048/748/592, gc cycles 2 Events: 8 queued, 8 completed Driver 0: standstill, SG min n/a, mspos 696, reads 20971, writes 2 timeouts 0 Driver 1: standstill, SG min n/a, mspos 376, reads 20971, writes 2 timeouts 0 Driver 2: standstill, SG min 29, mspos 792, reads 20967, writes 6 timeouts 0 Driver 3: standstill, SG min 31, mspos 536, reads 20967, writes 6 timeouts 0 Driver 4: standstill, SG min 41, mspos 856, reads 20968, writes 6 timeouts 0 Driver 5: standstill, SG min 0, mspos 444, reads 20965, writes 8 timeouts 0 Date/time: 2024-01-17 09:10:52 Slowest loop: 29.87ms; fastest: 0.06ms === Storage === Free file entries: 20 SD card 0 not detected, interface speed: 37.5MBytes/sec SD card longest read time 0.0ms, write time 0.0ms, max retries 0 === Move === DMs created 125, segments created 38, maxWait 43849148ms, bed compensation in use: mesh, height map offset -0.015, max steps late 0, ebfmin 0.00, ebfmax 0.00 no step interrupt scheduled Moves shaped first try 0, on retry 0, too short 0, wrong shape 0, maybepossible 0 === DDARing 0 === Scheduled moves 219265, completed 219265, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 7], CDDA state -1 === DDARing 1 === Scheduled moves 0, completed 0, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 0], CDDA state -1 === Heat === Bed heaters 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1, chamber heaters -1 -1 -1 -1, ordering errs 0 Heater 1 is on, I-accum = 0.2 === GCodes === Movement locks held by null, null HTTP* is doing "M122" in state(s) 0 Telnet* is idle in state(s) 0 File* is idle in state(s) 0 USB is idle in state(s) 0 Aux is idle in state(s) 0 Trigger* is idle in state(s) 0 Queue* is idle in state(s) 0 LCD is idle in state(s) 0 SBC is idle in state(s) 0 Daemon* is idle in state(s) 0 0, running macro Aux2 is idle in state(s) 0 Autopause* is idle in state(s) 0 File2* is idle in state(s) 0 Queue2 is idle in state(s) 0 Q0 segments left 0, axes/extruders owned 0x80000003 Code queue 0 is empty Q1 segments left 0, axes/extruders owned 0x0000000 Code queue 1 is empty === Filament sensors === check 121744554 clear 470790333 Extruder 0: pos 2222.23, errs: frame 20 parity 0 ovrun 0 pol 0 ovdue 0 === CAN === Messages queued 74655, received 0, lost 0, errs 39285668, boc 0 Longest wait 0ms for reply type 0, peak Tx sync delay 0, free buffers 50 (min 50), ts 41475/0/0 Tx timeouts 0,0,41475,0,0,33180 last cancelled message type 30 dest 127 === SBC interface === Transfer state: 5, failed transfers: 1, checksum errors: 1 RX/TX seq numbers: 45750/54145 SPI underruns 1, overruns 1 State: 5, disconnects: 1, timeouts: 1 total, 1 by SBC, IAP RAM available 0x258a4 Buffer RX/TX: 0/0-0, open files: 0 === Duet Control Server === Duet Control Server version 3.5.0-rc.2 (2023-12-18 12:42:49) Failed to deserialize the following properties: - MoveSegmentation -> Int32 from 2.0 Daemon: >> Doing macro daemon.g, started by system Code buffer space: 4096 Configured SPI speed: 8000000Hz, TfrRdy pin glitches: 0 Full transfers per second: 39.04, max time between full transfers: 388.2ms, max pin wait times: 36.6ms/1.1ms Codes per second: 0.91 Maximum length of RX/TX data transfers: 4561/1916Could this be the problem, what is resetting the SPI bus with only one error without retrying?
Do you think it is possible that this is an EMI/ESD problem or do you think it could be a software problem?
It appeared on the printer with the now shorter ribbon cable with two ferrit cores.
-
@chrishamm
ok, today I had the same issue again - but this time mid print.log from journalctl
Jan 17 21:52:15 Meltingplot-MBL-480-vaswsq DuetControlServer[26497]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 17 21:52:15 Meltingplot-MBL-480-vaswsq DuetControlServer[26497]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 17 21:52:15 Meltingplot-MBL-480-vaswsq DuetControlServer[26497]: [info] Aborted macro file daemon.g Jan 17 21:52:15 Meltingplot-MBL-480-vaswsq DuetControlServer[26497]: [warn] SPI connection has been reset Jan 17 21:52:15 Meltingplot-MBL-480-vaswsq DuetControlServer[26497]: [info] Aborted job file Jan 17 21:52:24 Meltingplot-MBL-480-vaswsq DuetControlServer[26497]: [info] Starting macro file daemon.g on channel DaemonM122
M122 === Diagnostics === RepRapFirmware for Duet 3 MB6HC version 3.5.0-rc.2 (2023-12-14 10:32:22) running on Duet 3 MB6HC v1.02 or later (SBC mode) Board ID: 08DJM-9P63L-DJ3T8-6JKD4-3SJ6K-9A77A Used output buffers: 1 of 40 (30 max) === RTOS === Static ram: 154844 Dynamic ram: 88856 of which 3488 recycled Never used RAM 95036, free system stack 122 words Tasks: SBC(2,ready,2.7%,398) HEAT(3,nWait,0.1%,324) Move(4,nWait,0.0%,213) CanReceiv(6,nWait,0.0%,942) CanSender(5,nWait,0.0%,334) CanClock(7,delaying,0.0%,342) TMC(4,nWait,21.1%,61) MAIN(2,running,76.1%,103) IDLE(0,ready,0.0%,30), total 100.0% Owned mutexes: HTTP(MAIN) === Platform === Last reset 23:40:19 ago, cause: software Last software reset at 2024-01-17 09:41, reason: User, FilamentSensors spinning, available RAM 95036, slot 0 Software reset code 0x600d HFSR 0x00000000 CFSR 0x00000000 ICSR 0x0044a000 BFAR 0x00000000 SP 0x00000000 Task SBC Freestk 0 n/a Error status: 0x00 MCU temperature: min 32.7, current 33.0, max 33.5 Supply voltage: min 24.0, current 24.1, max 24.2, under voltage events: 0, over voltage events: 0, power good: yes 12V rail voltage: min 11.7, current 12.2, max 12.8, under voltage events: 0 Heap OK, handles allocated/used 99/6, heap memory allocated/used/recyclable 2048/512/368, gc cycles 1 Events: 4 queued, 4 completed Driver 0: standstill, SG min n/a, mspos 904, reads 44429, writes 0 timeouts 0 Driver 1: standstill, SG min n/a, mspos 136, reads 44429, writes 0 timeouts 0 Driver 2: standstill, SG min n/a, mspos 520, reads 44428, writes 0 timeouts 0 Driver 3: standstill, SG min n/a, mspos 344, reads 44428, writes 0 timeouts 0 Driver 4: standstill, SG min n/a, mspos 328, reads 44428, writes 0 timeouts 0 Driver 5: standstill, SG min n/a, mspos 404, reads 44428, writes 0 timeouts 0 Date/time: 2024-01-18 09:21:29 Slowest loop: 2.26ms; fastest: 0.09ms === Storage === Free file entries: 20 SD card 0 not detected, interface speed: 37.5MBytes/sec SD card longest read time 0.0ms, write time 0.0ms, max retries 0 === Move === DMs created 125, segments created 38, maxWait 0ms, bed compensation in use: mesh, height map offset -0.015, max steps late 0, ebfmin 0.00, ebfmax 0.00 no step interrupt scheduled Moves shaped first try 0, on retry 0, too short 0, wrong shape 0, maybepossible 0 === DDARing 0 === Scheduled moves 265665, completed 265665, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 0], CDDA state -1 === DDARing 1 === Scheduled moves 0, completed 0, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 0], CDDA state -1 === Heat === Bed heaters 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1, chamber heaters -1 -1 -1 -1, ordering errs 0 === GCodes === Movement locks held by null, null HTTP* is doing "M122" in state(s) 0 Telnet is idle in state(s) 0 File* is idle in state(s) 0 USB is idle in state(s) 0 Aux is idle in state(s) 0 Trigger* is idle in state(s) 0 Queue* is idle in state(s) 0 LCD is idle in state(s) 0 SBC is idle in state(s) 0 Daemon* is idle in state(s) 0 0, running macro Aux2 is idle in state(s) 0 Autopause* is idle in state(s) 0 File2* is idle in state(s) 0 Queue2 is idle in state(s) 0 Q0 segments left 0, axes/extruders owned 0x80000007 Code queue 0 is empty Q1 segments left 0, axes/extruders owned 0x0000000 Code queue 1 is empty === Filament sensors === check 265137174 clear 413385405 Extruder 0: pos 2412.07, errs: frame 32 parity 0 ovrun 0 pol 0 ovdue 0 === CAN === Messages queued 81508, received 0, lost 0, errs 42912260, boc 0 Longest wait 0ms for reply type 0, peak Tx sync delay 0, free buffers 50 (min 50), ts 45282/0/0 Tx timeouts 0,0,45282,0,0,36226 last cancelled message type 30 dest 127 === SBC interface === Transfer state: 5, failed transfers: 1, checksum errors: 1 RX/TX seq numbers: 1414/41139 SPI underruns 1, overruns 1 State: 5, disconnects: 1, timeouts: 1 total, 1 by SBC, IAP RAM available 0x258a4 Buffer RX/TX: 0/0-0, open files: 0 === Duet Control Server === Duet Control Server version 3.5.0-rc.2 (2023-12-18 12:42:49) Failed to deserialize the following properties: - MoveSegmentation -> Int32 from 2.0 Daemon: >> Doing macro daemon.g, started by system Code buffer space: 4096 Configured SPI speed: 8000000Hz, TfrRdy pin glitches: 0 Full transfers per second: 39.03, max time between full transfers: 273.4ms, max pin wait times: 32.3ms/1.6ms Codes per second: 0.90 Maximum length of RX/TX data transfers: 7368/2068eventlog
2024-01-17 15:31:51 File 0:/gcodes/PP_hulle2_2024_01_15_0.35mm_PP_MBL480_1d13h13m.gcode selected for printing 2024-01-17 15:31:51 G10 P0 R220 2024-01-17 15:31:51 G10 P0 R215 S220 2024-01-17 21:52:15 Warning: SPI connection has been reset 2024-01-17 21:52:15 Connection to SBC established! 2024-01-18 06:50:34 === Diagnostics === RepRapFirmware for Duet 3 MB6HC version 3.5.0-rc.2 (2023-12-14 10:32:22) running on Duet 3 MB6HC v1.02 or later (SBC mode) Board ID: 08DJM-9P63L-DJ3T8-6JKD4-3SJ6K-9A77A Used output buffers: 1 of 40 (18 max)What is interesting is, that the print job was aborted, but the homing was still there.
It looks like a state glitch to me. DSF is already at DataExchange, while RRF is still in HeaderExchange.
-
@chrishamm
I don't know how the program can get there, but I guess it is because there is no protection for the response code against bit errors. What will happen if the following will occure.// the ExchangeResponse(TransferResponse::BadHeaderChecksum) or txResponse has a bit error from // 0101 to 0001 or from 0001 to 0101 // the following will be true else if (rxResponse == TransferResponse::BadHeaderChecksum || txResponse == TransferResponse::BadHeaderChecksum) { // Failed to exchange header, restart the full transfer checksumErrors++; ExchangeHeader(); } // and RRF will stay in ExchangeHeader while DSF will be in ExchangeData() // after the first transfer RRF will abort the transfer with const uint32_t checksum = CalcCRC32(reinterpret_cast<const char *>(&rxHeader), sizeof(TransferHeader) - sizeof(uint32_t)); if (rxHeader.crcHeader != checksum) { if (reprap.Debug(Module::SbcInterface)) { debugPrintf("Bad header CRC (expected %08" PRIx32 ", got %08" PRIx32 ")\n", rxHeader.crcHeader, checksum); } ExchangeResponse(TransferResponse::BadHeaderChecksum); break; } // which will endup in DSF default: _logger.Warn("Restarting data response exchange because a bad code was received (0x{0:x8})", response); ExchangeResponse(TransferResponse.BadResponse); continue; // causing DSF and RRF to restart the connection else { // Restart the full transfer RestartTransfer(rxResponse != TransferResponse::BadResponse); }Maybe I'm wrong with this assessment - it's hard to understand and debug the code just by reading it.
//EDIT:
the above said does not fit to the followingfailed transfers: 1, checksum errors: 1 SPI underruns 1, overruns 1 disconnects: 1, timeouts: 1 total, 1 by SBCdoes it mean, that there was one crc error on rrf side which caused one transfer to fail and one disconnect which was a timeout on the dsf side?
// \\EditWithout any questions the printer is in an harsh environment and there is a lot of RF noise - but I don't understand why the printer stops printing - without any "hard" reason, as I can easily resume the print with M916 (after create the ressurect.g manually)
As I was looking at the protocol the following caught my attention
// Change the protocol version if necessary ushort lastProtocolVersion = _txHeader.ProtocolVersion; if (_rxHeader.ProtocolVersion != lastProtocolVersion && (_rxHeader.ProtocolVersion <= Consts.ProtocolVersion || Settings.UpdateOnly)) { _txHeader.ProtocolVersion = _rxHeader.ProtocolVersion; WriteCRC(); ExchangeResponse(TransferResponse.BadResponse); continue; }If there is an EMI event which will cause a biterror in the protocol version field of the header from the rrf to the dsf which is still within
_rxHeader.ProtocolVersion <= Consts.ProtocolVersion, it will silently change the protocol version without an crc check and initiate a restart of the transfer from dsf side. Causing rrf to refuse the second transfer attempt with:if (rxHeader.protocolVersion != SbcProtocolVersion) { ExchangeResponse(TransferResponse::BadProtocolVersion); break; } -
@timschneider There is handling for unexpected data, in that event the whole transfer is supposed to be restarted. Also, response code 5 means there was a header checksum error (in that case detected by RRF, see src/SPI/Shared/TransferResponse.cs -> BadHeaderChecksum). RRF should simply restart from the state where the header transfer was set up and only give up after the third failed attempt, and likewise DSF should be in a state where should accept header data. You may get further information by hooking up a serial monitor to the Duet itself in case it happens again.
At the moment I don't have the time to dig into it much deeper, but I've created a new GitHub issue so this report isn't lost: https://github.com/Duet3D/DuetSoftwareFramework/issues/196
-
@chrishamm
thank you for opening the issue on github and your response. I think this issue/bug is not time critical, as it is not happening to many of the users, or with other words, only I'm reporting it, as far as I know.I was able to capture the following more events
Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x9855c57b, got 0xf48e73cb) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x9855c57b, got 0xf48e73cb) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x9855c57b, got 0xf48e73cb) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 20 01:39:48 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been resetJan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 20 09:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been resetJan 20 17:07:49 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 20 17:07:49 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 20 17:07:49 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been resetJan 21 06:30:09 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 21 06:30:09 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 21 06:30:09 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been resetso it looks like it, if the response code from RRF to DSF/DCS can make its way through, the retry mechanism is working. But if, for a reason i don't know yet, the response code is not received or corrupted,the retry mechanism is not used/EDIT/a state glitch can occur, causing the retry mechanis to fail, as it is not retrying the full transfer /EDIT/.But anyhow it looks strange to me, that even the crc32 checksum in three different messages is wrong with the same value - this might be setup specific - I'll try the same setup with lower bus speed and then change the rock 4c+ with an RPi4b - both 4GB.
Ok - no it is the software - it is because of a state glitch - RRF is in ExchangeHeader and DSF/DCS is in DataExchange.The Error message of DCS is
[warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610)which means, that DCS is in ExchangeData.
If it is was in ExchangeHeader, the error message would be:
_logger.Warn("Bad header CRC32 (expected 0x{0:x8}, got 0x{1:x8})", _rxHeader.ChecksumHeader32, crc32);The response code from RRF is
BadHeaderChecksum = 5which means, that RRF is in ExchangeHeader.
and the CRC32 differs, maybe because of different calculation methods (length of data to check):
# CRC32 of Header uint crc32 = CRC32.Calculate(_rxHeaderBuffer[..12].Span);# CRC32 of Data uint crc32 = CRC32.Calculate(_rxBuffer[.._rxHeader.DataLength].Span);I'll check how I can hookup another RPi on the USB Port of the Duet and store the data - but it will take some time, as I'm not able to reach the usb port from outside of the enclosure.
/EDIT/
Some more log events, so I think it can be seen, that it is not random, it follows a pattern and hence is somehow software/protocol connected.Jan 21 06:30:09 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 21 06:30:09 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 21 06:30:09 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 22 04:29:32 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 22 04:29:32 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 22 04:29:32 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 22 13:42:47 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 22 13:42:47 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 22 13:42:47 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 23 18:42:59 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 23 18:42:59 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 23 18:42:59 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 23 20:41:35 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x1a039956, got 0xc3e0e610) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 23 21:43:57 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 24 06:16:21 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Restarting data response exchange because a bad code was received (0x00000005) Jan 24 06:16:21 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 24 06:16:21 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x02d42d70, got 0x6a5bb60f) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x02d42d70, got 0x6a5bb60f) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Bad data CRC32 (expected 0x02d42d70, got 0x6a5bb60f) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] Daemon: Aborting orphaned macro file daemon.g Jan 24 23:07:27 Meltingplot-MBL-480-vaswsq DuetControlServer[16087]: [warn] SPI connection has been reset -
@chrishamm
Short update
I've updated the unit to 3.5.0-rc.3+.
Since then, the error no longer occurs. The uptime of the machine is approx. 160 hours, previously the error occurred every 48 hours at the latest.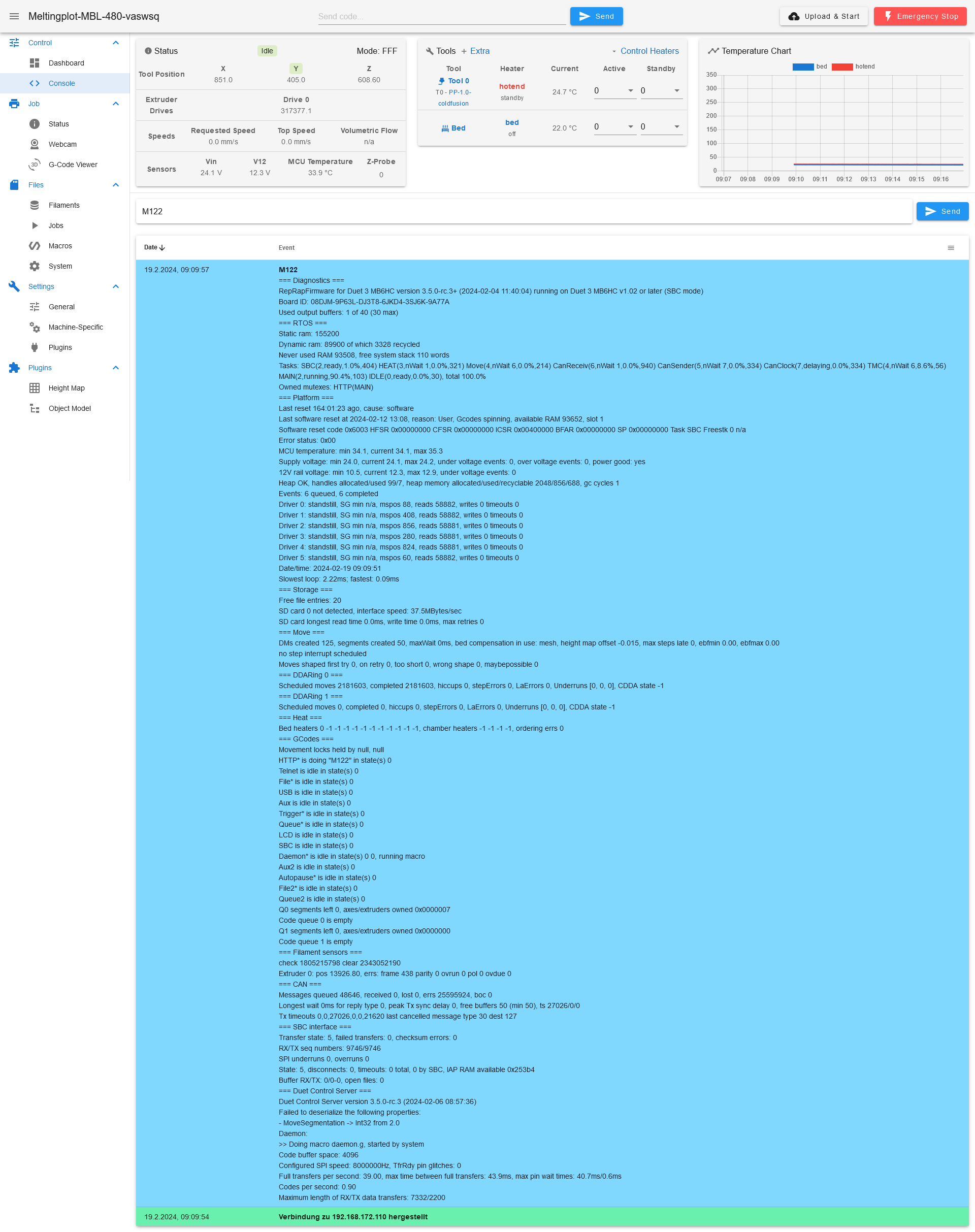
So that makes me think that is is/was a software bug.
I've checked the CRC and retry mechanis in software and hardware.
(see next post)
so it can be seen that the mechanis is working as expected.
I've also tried to add a catch for the StateGlitch:

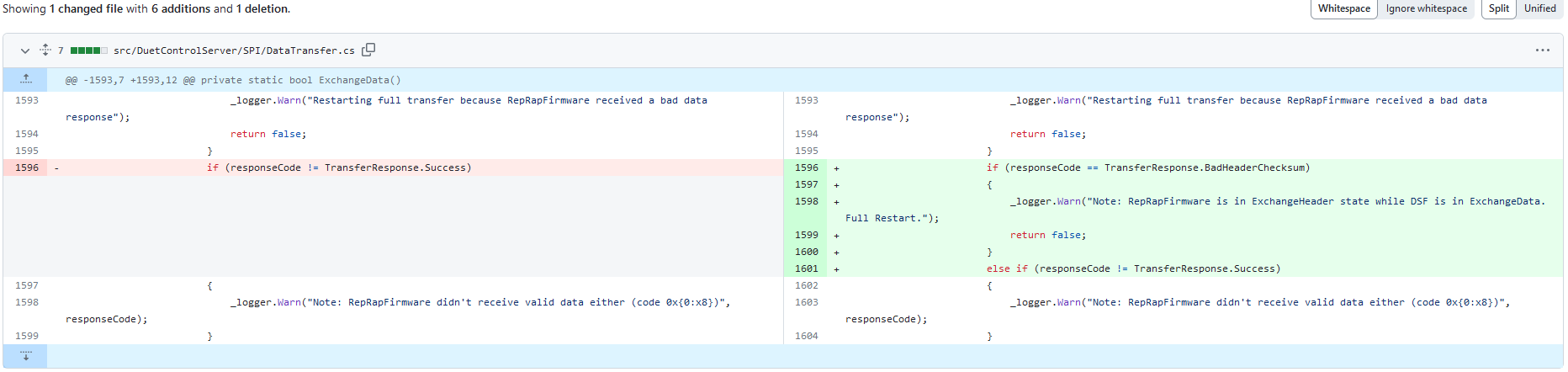
but as said above, the error did not occure and I was not able to see the warning in the log.
In order to get a better understanding of the protocol I wrote a unittest for it, but I needed to add an interface and remove the sealed attribute of the classes to get it working (sorry, I'm not an c# expert)
https://github.com/timschneider/DuetSoftwareFramework/commit/49baa620f5b88fded575f4a2f5eb2c72f9e02a8c -
Feb 19 10:48:54 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x327b1b52, got 0x8ac77c37) Feb 19 10:48:54 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x70fcf9e9, got 0x3ce8c282) Feb 19 10:48:54 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x70fcf9e9, got 0x36675c5a) Feb 19 10:48:54 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xe3c9f499, got 0x3677b00a) Feb 19 10:48:55 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x0e9a3913, got 0x044b0f03) Feb 19 10:48:55 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x6843bcdb, got 0x93409691) Feb 19 10:48:55 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xa1ecdcf9, got 0xc6324037) Feb 19 10:48:55 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xe8a4204b, got 0xe8a4205b) Feb 19 10:48:56 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x3a63c26e, got 0xa66b4b8f) Feb 19 10:48:56 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x87654922, got 0x87454922) Feb 19 10:48:56 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x9c11a409, got 0xe053527c) Feb 19 10:48:56 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x9d292d20, got 0xa9115df4) Feb 19 10:48:56 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xfe4934ec, got 0x50a44c41) Feb 19 10:48:57 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x527ba884, got 0x527ba88c) Feb 19 10:48:57 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xf15d15d7, got 0x64d93175) Feb 19 10:48:57 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xaa2a3f9d, got 0xaa2a7f9d) Feb 19 10:48:57 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x4d60025d, got 0x5566223a) Feb 19 10:48:58 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x4cc9bf77, got 0x9779b6c5) Feb 19 10:48:58 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x0f522895, got 0x1aa6296e) Feb 19 10:48:58 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xeef407ba, got 0x09b68467) Feb 19 10:48:58 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xf04c0bce, got 0xf04c4bce) Feb 19 10:48:58 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x9cf5af45, got 0x92e6fefd) Feb 19 10:48:59 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xf72e0495, got 0x73640a6f) Feb 19 10:48:59 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x658ad339, got 0x2a709772) Feb 19 10:48:59 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x73ef8b84, got 0x69b611af) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xe6e34851, got 0xec3ff255) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x8bfedddf, got 0xb1918aef) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x8bfedddf, got 0xf1c231fb) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x4b8ed792, got 0x44d6ddfe) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Restarting data response exchange because a bad code was received (0x00000000) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x4d427cea, got 0x4e2986d0) Feb 19 10:49:00 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xbbdcbbb2, got 0x22f87c33) Feb 19 10:49:01 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xe6956475, got 0x40e26fc1) Feb 19 10:49:01 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xa6af861f, got 0xb286b01b) Feb 19 10:49:01 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x2d81504a, got 0x8bf65bfe) Feb 19 10:49:02 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xb45df60c, got 0xd71445a1) Feb 19 10:49:02 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x4298777d, got 0x6c7c997c) Feb 19 10:49:02 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Restarting data response exchange because a bad code was received (0x00000000) Feb 19 10:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x75852309, got 0x48004aa8) Feb 19 10:49:03 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Restarting full transfer because a bad header response was received (0x00000000) Feb 19 10:49:04 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x7dfc40ea, got 0x7dfc50ea) Feb 19 10:49:04 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x5e849b1e, got 0x5ea49b1e) Feb 19 10:49:04 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0x3eeddc39, got 0x00b384d8) Feb 19 10:49:04 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x9ba34d50, got 0x86145d34) Feb 19 10:49:04 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x90ddb799, got 0x90ddb719) Feb 19 10:49:04 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0xf80dad40, got 0xff04059c) Feb 19 10:49:05 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x38cc67c8, got 0x00812128) Feb 19 10:49:05 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad header CRC32 (expected 0x2b368b1f, got 0xfdd865b1) Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xa7af53eb, got 0x084557ee) Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xa7af53eb, got 0x4460b29e) Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Bad data CRC32 (expected 0xa7af53eb, got 0xbe94aa1b) Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [info] Connection to Duet established Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] Daemon: Aborting orphaned macro file daemon.g Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [info] Aborted macro file daemon.g Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [warn] SPI connection has been reset Feb 19 10:49:06 Meltingplot-MBL-480-vaswsq DuetControlServer[739]: [info] Aborted job file -
@chrishamm
ok back on rc.2 - just 24h later, the error is back again. is there some lock missing? there is the out of order execution bug in rc.2 which is fixed in rc.3 - is it possible that two different requests are send?Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Bad data CRC32 (expected 0xcca30993, got 0x5c381b68) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Bad data CRC32 (expected 0xcca30993, got 0x5c381b68) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Bad data CRC32 (expected 0xcca30993, got 0x5c381b68) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Note: RepRapFirmware didn't receive valid data either (code 0x00000005) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Lost connection to Duet (SPI connection reset because the number of maximum retries has been exceeded) Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [info] Connection to Duet established Feb 20 17:50:19 Meltingplot-MBL-480-vaswsq DuetControlServer[8583]: [warn] Daemon: Aborting orphaned macro file daemon.g20.2.2024, 21:34:18 m122 === Diagnostics === RepRapFirmware for Duet 3 MB6HC version 3.5.0-rc.2 (2023-12-14 10:32:22) running on Duet 3 MB6HC v1.02 or later (SBC mode) Board ID: 08DJM-9P63L-DJ3T8-6JKD4-3SJ6K-9A77A Used output buffers: 1 of 40 (28 max) === RTOS === Static ram: 154844 Dynamic ram: 88296 of which 4048 recycled Never used RAM 95036, free system stack 143 words Tasks: SBC(2,ready,22.9%,390) HEAT(3,nWait,0.8%,324) Move(4,nWait,0.0%,213) CanReceiv(6,nWait,0.0%,942) CanSender(5,nWait,0.0%,334) CanClock(7,delaying,0.2%,342) TMC(4,nWait,184.3%,61) MAIN(2,running,467.4%,103) IDLE(0,ready,0.0%,30), total 675.6% Owned mutexes: HTTP(MAIN) === Platform === Last reset 30:02:03 ago, cause: software Last software reset at 2024-02-19 10:50, reason: User, Gcodes spinning, available RAM 93772, slot 0 Software reset code 0x6003 HFSR 0x00000000 CFSR 0x00000000 ICSR 0x00400000 BFAR 0x00000000 SP 0x00000000 Task SBC Freestk 0 n/a Error status: 0x00 MCU temperature: min 33.5, current 33.8, max 34.1 Supply voltage: min 24.0, current 24.1, max 24.2, under voltage events: 0, over voltage events: 0, power good: yes 12V rail voltage: min 10.8, current 12.3, max 12.8, under voltage events: 0 Heap OK, handles allocated/used 99/4, heap memory allocated/used/recyclable 2048/140/36, gc cycles 0 Events: 0 queued, 0 completed Driver 0: standstill, SG min n/a, mspos 376, reads 33680, writes 0 timeouts 0 Driver 1: standstill, SG min n/a, mspos 216, reads 33680, writes 0 timeouts 0 Driver 2: standstill, SG min n/a, mspos 616, reads 33680, writes 0 timeouts 0 Driver 3: standstill, SG min n/a, mspos 776, reads 33680, writes 0 timeouts 0 Driver 4: standstill, SG min n/a, mspos 72, reads 33680, writes 0 timeouts 0 Driver 5: standstill, SG min n/a, mspos 876, reads 33681, writes 0 timeouts 0 Date/time: 2024-02-20 21:34:17 Slowest loop: 2.16ms; fastest: 0.07ms === Storage === Free file entries: 20 SD card 0 not detected, interface speed: 37.5MBytes/sec SD card longest read time 0.0ms, write time 0.0ms, max retries 0 === Move === DMs created 125, segments created 38, maxWait 0ms, bed compensation in use: mesh, height map offset -0.015, max steps late 0, ebfmin 0.00, ebfmax 0.00 no step interrupt scheduled Moves shaped first try 0, on retry 0, too short 0, wrong shape 0, maybepossible 0 === DDARing 0 === Scheduled moves 2160579, completed 2160579, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 0], CDDA state -1 === DDARing 1 === Scheduled moves 0, completed 0, hiccups 0, stepErrors 0, LaErrors 0, Underruns [0, 0, 0], CDDA state -1 === Heat === Bed heaters 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1, chamber heaters -1 -1 -1 -1, ordering errs 0 === GCodes === Movement locks held by null, null HTTP* is doing "M122" in state(s) 0 Telnet is idle in state(s) 0 File* is idle in state(s) 0 USB is idle in state(s) 0 Aux is idle in state(s) 0 Trigger* is idle in state(s) 0 Queue is idle in state(s) 0 LCD is idle in state(s) 0 SBC is idle in state(s) 0 Daemon* is idle in state(s) 0 0, running macro Aux2 is idle in state(s) 0 Autopause is idle in state(s) 0 File2* is idle in state(s) 0 Queue2 is idle in state(s) 0 Q0 segments left 0, axes/extruders owned 0x80000007 Code queue 0 is empty Q1 segments left 0, axes/extruders owned 0x0000000 Code queue 1 is empty === Filament sensors === check 0 clear 1002479064 Extruder 0: pos 13983.05, errs: frame 13 parity 0 ovrun 0 pol 0 ovdue 0 === CAN === Messages queued 215112, received 0, lost 0, errs 113194497, boc 0 Longest wait 0ms for reply type 0, peak Tx sync delay 0, free buffers 50 (min 50), ts 119507/0/0 Tx timeouts 0,0,119507,0,0,95605 last cancelled message type 30 dest 127 === SBC interface === Transfer state: 5, failed transfers: 0, checksum errors: 3 RX/TX seq numbers: 7204/210 SPI underruns 3, overruns 3 State: 5, disconnects: 1, timeouts: 1 total, 1 by SBC, IAP RAM available 0x258a4 Buffer RX/TX: 0/0-0, open files: 0 === Duet Control Server === Duet Control Server version 3.5.0-rc.2 (2023-12-18 12:42:49) Failed to deserialize the following properties: - MoveSegmentation -> Int32 from 2.0 Daemon: >> Doing macro daemon.g, started by system Code buffer space: 4096 Configured SPI speed: 8000000Hz, TfrRdy pin glitches: 0 Full transfers per second: 39.03, max time between full transfers: 234.2ms, max pin wait times: 33.2ms/1.2ms Codes per second: 0.90 Maximum length of RX/TX data transfers: 7192/3448next thing i'll do is to add the catch code from above to the rc.2 base in order to get the state glicht back in sync.
-
@timschneider Thanks for the dump. I've inspected the code once again and I think DSF should restart the full transfer in case that
0x00000005response is received (which it currently does not). I don't know why your particular setup gets out of order SPI transfers at some point; leaving a USB terminal connected over a longer period might reveal why.The other bugs I fixed since rc.2 are completely unrelated to the SPI link.
-
@chrishamm
Thanks for the fix - in the meantime, I've discarded the idea of using a different sbc than a raspberrypi. The problem was "gone" in rc3, which makes me suspect it is/was a software related issue, but ultimately I couldn't track it down. In the meantime, a customer had a similar problem with 3.4.6 -> so we replaced the rock pi 4c plus with a raspberry pi 4b.@droftarts
Perhaps it should be mentioned in the documentation that any other Sbc than a raspberrypi can lead to random errors of all kinds and is strongly discouraged, even if it works at first glance. -
@timschneider I tried a RockPi SBC a while ago and never managed to get it working even though it appears to work for others, so I won't make a general recommendation about what SBC to use or not. The SBC type we've always recommended is the RaspPi (especially because it does not require custom wiring) but AFAIR nVidia Tegra SBCs have been reported to work just as well.

